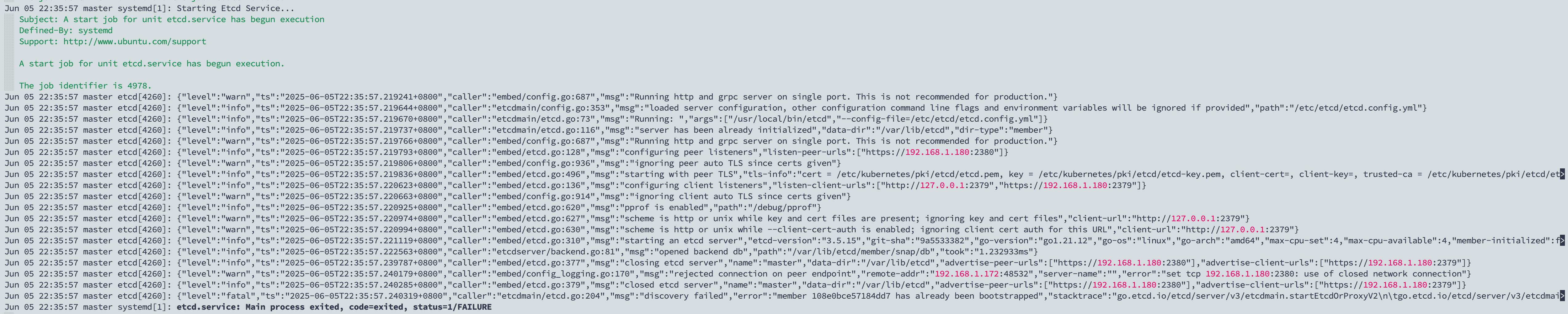
Jun 05 22:35:57 master etcd[4260]: {"level":"warn","ts":"2025-06-05T22:35:57.219241+0800","caller":"embed/config.go:687","msg":"Running http and grpc server on single port. This is not recommended for production."}
Jun 05 22:35:57 master etcd[4260]: {"level":"info","ts":"2025-06-05T22:35:57.219644+0800","caller":"etcdmain/config.go:353","msg":"loaded server configuration, other configuration command line flags and environment variables will be ignored if provided","path":"/etc/etcd/etcd.config.yml"}
Jun 05 22:35:57 master etcd[4260]: {"level":"info","ts":"2025-06-05T22:35:57.219670+0800","caller":"etcdmain/etcd.go:73","msg":"Running: ","args":["/usr/local/bin/etcd","--config-file=/etc/etcd/etcd.config.yml"]}
Jun 05 22:35:57 master etcd[4260]: {"level":"info","ts":"2025-06-05T22:35:57.219737+0800","caller":"etcdmain/etcd.go:116","msg":"server has been already initialized","data-dir":"/var/lib/etcd","dir-type":"member"}
Jun 05 22:35:57 master etcd[4260]: {"level":"warn","ts":"2025-06-05T22:35:57.219766+0800","caller":"embed/config.go:687","msg":"Running http and grpc server on single port. This is not recommended for production."}
Jun 05 22:35:57 master etcd[4260]: {"level":"info","ts":"2025-06-05T22:35:57.219793+0800","caller":"embed/etcd.go:128","msg":"configuring peer listeners","listen-peer-urls":["https://192.168.1.180:2380"]}
Jun 05 22:35:57 master etcd[4260]: {"level":"warn","ts":"2025-06-05T22:35:57.219806+0800","caller":"embed/config.go:936","msg":"ignoring peer auto TLS since certs given"}
Jun 05 22:35:57 master etcd[4260]: {"level":"info","ts":"2025-06-05T22:35:57.219836+0800","caller":"embed/etcd.go:496","msg":"starting with peer TLS","tls-info":"cert = /etc/kubernetes/pki/etcd/etcd.pem, key = /etc/kubernetes/pki/etcd/etcd-key.pem, client-cert=, client-key=, trusted-ca = /etc/kubernetes/pki/etcd/et>
Jun 05 22:35:57 master etcd[4260]: {"level":"info","ts":"2025-06-05T22:35:57.220623+0800","caller":"embed/etcd.go:136","msg":"configuring client listeners","listen-client-urls":["http://127.0.0.1:2379","https://192.168.1.180:2379"]}
Jun 05 22:35:57 master etcd[4260]: {"level":"warn","ts":"2025-06-05T22:35:57.220663+0800","caller":"embed/config.go:914","msg":"ignoring client auto TLS since certs given"}
Jun 05 22:35:57 master etcd[4260]: {"level":"info","ts":"2025-06-05T22:35:57.220925+0800","caller":"embed/etcd.go:620","msg":"pprof is enabled","path":"/debug/pprof"}
Jun 05 22:35:57 master etcd[4260]: {"level":"warn","ts":"2025-06-05T22:35:57.220974+0800","caller":"embed/etcd.go:627","msg":"scheme is http or unix while key and cert files are present; ignoring key and cert files","client-url":"http://127.0.0.1:2379"}
Jun 05 22:35:57 master etcd[4260]: {"level":"warn","ts":"2025-06-05T22:35:57.220994+0800","caller":"embed/etcd.go:630","msg":"scheme is http or unix while --client-cert-auth is enabled; ignoring client cert auth for this URL","client-url":"http://127.0.0.1:2379"}
Jun 05 22:35:57 master etcd[4260]: {"level":"info","ts":"2025-06-05T22:35:57.221119+0800","caller":"embed/etcd.go:310","msg":"starting an etcd server","etcd-version":"3.5.15","git-sha":"9a5533382","go-version":"go1.21.12","go-os":"linux","go-arch":"amd64","max-cpu-set":4,"max-cpu-available":4,"member-initialized":f>
Jun 05 22:35:57 master etcd[4260]: {"level":"info","ts":"2025-06-05T22:35:57.222563+0800","caller":"etcdserver/backend.go:81","msg":"opened backend db","path":"/var/lib/etcd/member/snap/db","took":"1.232933ms"}
Jun 05 22:35:57 master etcd[4260]: {"level":"info","ts":"2025-06-05T22:35:57.239787+0800","caller":"embed/etcd.go:377","msg":"closing etcd server","name":"master","data-dir":"/var/lib/etcd","advertise-peer-urls":["https://192.168.1.180:2380"],"advertise-client-urls":["https://192.168.1.180:2379"]}
Jun 05 22:35:57 master etcd[4260]: {"level":"warn","ts":"2025-06-05T22:35:57.240179+0800","caller":"embed/config_logging.go:170","msg":"rejected connection on peer endpoint","remote-addr":"192.168.1.172:48532","server-name":"","error":"set tcp 192.168.1.180:2380: use of closed network connection"}
Jun 05 22:35:57 master etcd[4260]: {"level":"info","ts":"2025-06-05T22:35:57.240285+0800","caller":"embed/etcd.go:379","msg":"closed etcd server","name":"master","data-dir":"/var/lib/etcd","advertise-peer-urls":["https://192.168.1.180:2380"],"advertise-client-urls":["https://192.168.1.180:2379"]}
Jun 05 22:35:57 master etcd[4260]: {"level":"fatal","ts":"2025-06-05T22:35:57.240319+0800","caller":"etcdmain/etcd.go:204","msg":"discovery failed","error":"member 108e0bce57184dd7 has already been bootstrapped","stacktrace":"go.etcd.io/etcd/server/v3/etcdmain.startEtcdOrProxyV2\n\tgo.etcd.io/etcd/server/v3/etcdmai>
Jun 05 22:35:57 master systemd[1]: etcd.service: Main process exited, code=exited, status=1/FAILURE